什么是 ShardingSphere
首先引用官网上的介绍
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
简单来说ShardingSphere是一款可广泛使用的生产级分表分库中间件,目前有超过10000个GitHub使用它,可以说其优秀的设计值得我们细说,如果你的项目需要考虑一款生产级别的分表分库中间件,这个绝对是首选。
说到 ShardingSphere 的起源,我们不得不提 Sharding-JDBC 框架,该框架是一款起源于当当网内部的应用框架,并于 2017 年初正式开源。从 Sharding-JDBC 到 Apache 顶级项目,ShardingSphere 的发展经历了不同的演进阶段。
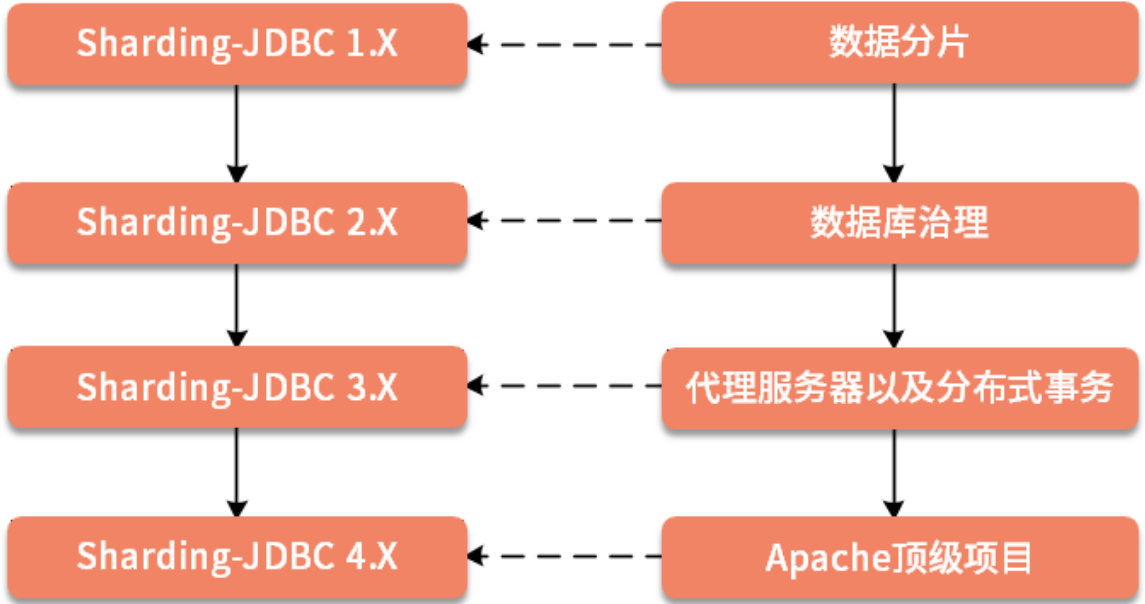
目前ShardingSphere最新版本是5.X,最新版本是5.3.2,从5.0版本开始ShardingSphere开始进行重大重构,可以说5.0完全不兼容之前的版本,我们要讨论的版本就是最新的5.X版本。
分表分库分为垂直分片和水平分表两种,两者可以同时进行,目前市面上的主流分表分库产品主要有三种:
- 客户端分片 典型的中间件包括阿里巴巴的 TDDL 以及ShardingSphere
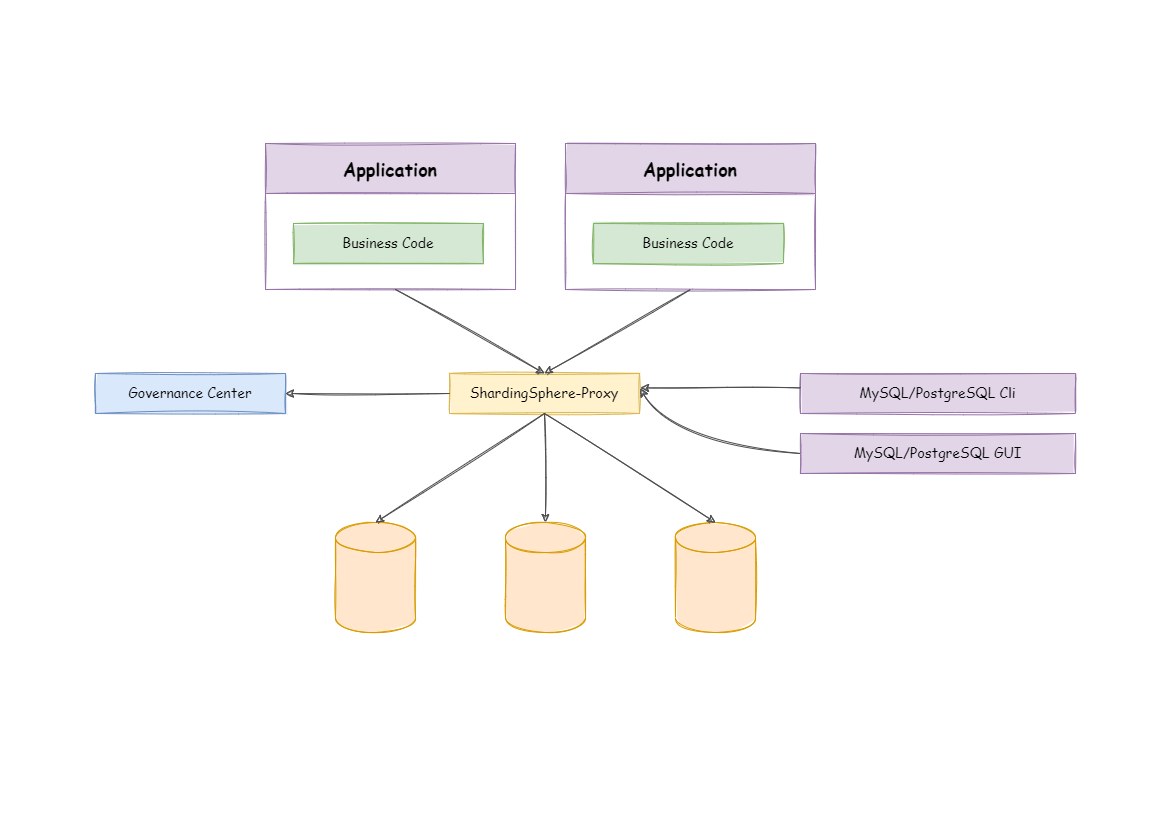
- 代理服务器分片 常见的开源框架有阿里的 Cobar 以及民间开源社区的 MyCat。而在 ShardingSphere 3.X 版本中,也添加了 Sharding-Proxy 模块来实现代理服务器分片。
- 分布式数据库 以PG为代表的CockroachDB,以及以MySql为代表的TiDB
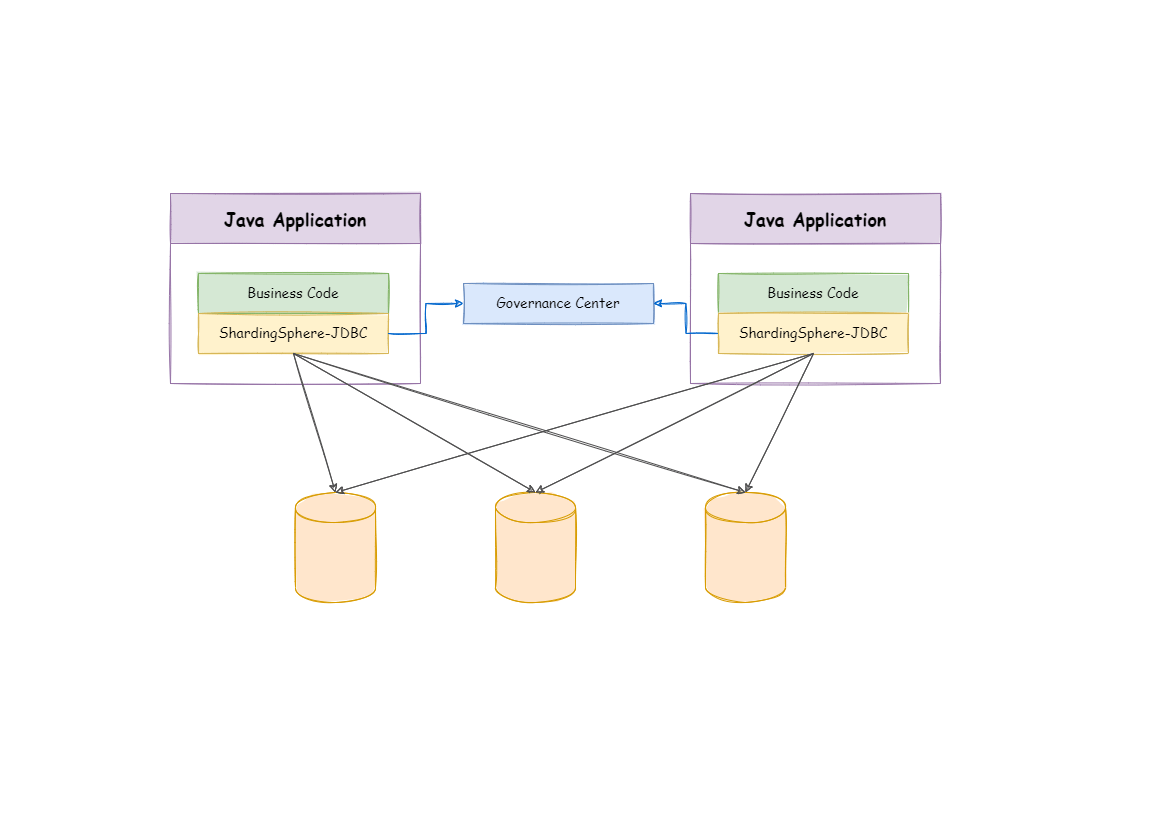
ShardingSphere分布式部署架构
客户端分片
代理服务器分片
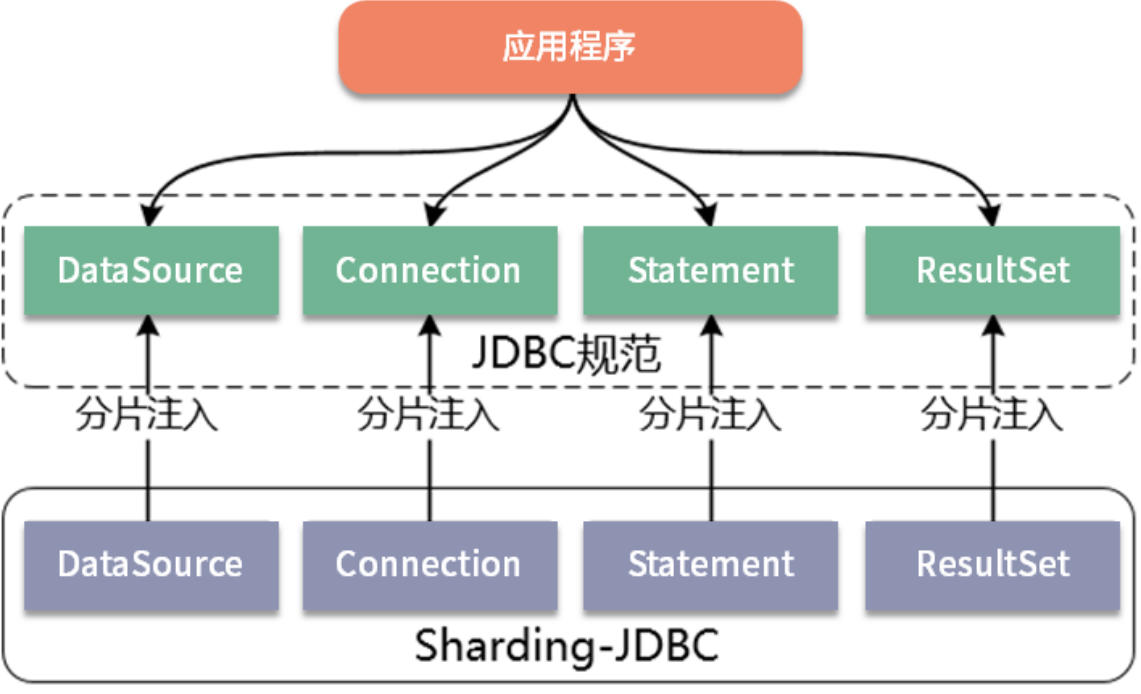
ShardingSphere的设计原理
Sharding-JDBC 的定位是一个轻量级 Java 框架,在 JDBC 层提供了扩展性服务。我们知道 JDBC 是一种开发规范,指定了 DataSource、Connection、Statement、PreparedStatement、ResultSet 等一系列接口。而各大数据库供应商通过实现这些接口提供了自身对 JDBC 规范的支持,使得 JDBC 规范成为 Java 领域中被广泛采用的数据库访问标准。
基于这一点,Sharding-JDBC 一开始的设计就完全兼容 JDBC 规范,Sharding-JDBC 对外暴露的一套分片操作接口与 JDBC 规范中所提供的接口完全一致。开发人员只需要了解 JDBC,就可以使用 Sharding-JDBC 来实现分库分表,Sharding-JDBC 内部屏蔽了所有的分片规则和处理逻辑的复杂性。显然,这种方案天生就是一种具有高度兼容性的方案,能够为开发人员提供最简单、最直接的开发支持。
客户端分片的实现分为几个步骤:
- SQL解析
- 路由
- 改写
- 执行
- 执行结果归并
ShardingSphere源代码解读
首先看一下项目结构
阅读源代码有很多种方式,可以基于上面的分片执行步骤为切入点,也可以基于JDBC开发规范进行切入,其实我们习惯于从Hello Word开始,基于分片执行步骤可以强化我们的理解,从上面的项目我们可以看到有几大模块:
- infra
- feature
- parser
- jdbc
- kernel
等还有很多其它模块,我们先看上面主流的三大模块,infra属于最高层的模块,涵盖了我们上面列出的5大步骤,分别对应parser,route,rewrite,excutor,merge;parser主要是交给parser模块解析,route底层的立即主要分散在feature和kernel,主要由7种路由方式:
- Single 单播
- Shardings 根据SQL路由,标准默认
- SqlRouteFixture 默认固定路由
- SqlrouteFailFixture 无效路由
- ShadowSql 影子库路由
影子库:实际中使用的数据库的完整数据库数据拷贝,比如进行压测数据隔离的影子数据库,与生产数据库应当使用相同的配置。 目的:主要是为了环境隔离,将数据进行隔离:数据库(实例)隔离,数据表隔离等。 在全链路压测环境下,主要实现的是压测数据和其它环境(生产)数据的隔离。
- ReadwriteSplitting 读写分离理由
- Broadcast 广播理由
Single主要的代码在kernel模块,而其他几个主要是在feature模块。
从Hello Word开始带你入门
项目里面虽然有example,但是确实结构混乱,也不完整,这里找到一篇官方的例子可以参考,例子主要分为两段,第一段是创建数据源,第二段是使用数据源执行SQL,如果你熟悉JDBC的话,以上的用法除了配置外,其它的是不是毫无违和感。
主要对象是ShardingSphereDataSourceFactory,下面带你进行源代码解读。
我们从createDataSource方法看起,主要是new 了一个ShardingSphereDataSource对象,如下:
public ShardingSphereDataSource(final String databaseName, final ModeConfiguration modeConfig) throws SQLException {
this.databaseName = databaseName;
contextManager = createContextManager(databaseName, modeConfig, new LinkedHashMap<>(), new LinkedList<>(), new Properties());
jdbcContext = new JDBCContext(contextManager.getDataSourceMap(databaseName));
contextManagerInitializedCallback(databaseName, contextManager);
}
这里面内容虽然少,但是大有文章,为避免进入代码海洋,我只是做大致解读:
- createContextManager方法用来创建ContextManager对象,这个对象承载了所有配置信息,包括分片分表规则,数据源信息(datasource)等,ContextManager初始化时会根据上下文初始信息来构造上面说的内容,ContextManager采用ShardingSphere提供的SPI机制加载ContextManagerBuilder,ContextManagerBuilder为一个SPI扩展接口,这个接口3个实现,主要是根据不同的部署模式进行上下文加载,主要是集群和单机模式。
- 有了ContextManager之后我们就可以数据源名称从ContextManager缓存的数据源对象集合来获取DataSource信息了,有了DataSource之后那么后面就好办了,我们根据DataSource创建Connection,Statement,然后执行SQL。
以上获取到到DataSource实际是一个ShardingSphereDataSource,我们查看其getConnection方法可以知道Connection是怎么创建的,其实是最终调用org.apache.shardingsphere.driver.state.DriverStateContext#getConnection的方法处理,使用也是SPI的机制来加载DriverState。
public static Connection getConnection(final String databaseName, final ContextManager contextManager, final JDBCContext jdbcContext) {
return TypedSPILoader.getService(
DriverState.class, contextManager.getInstanceContext().getInstance().getState().getCurrentState().name()).getConnection(databaseName, contextManager, jdbcContext);
}
DriverState有三种实现,默认是OKDriverState,我们可以看到这个类的getConnection方法创建的其实是ShardingSphereConnection对象
@Override
public Connection getConnection(final String databaseName, final ContextManager contextManager, final JDBCContext jdbcContext) {
return new ShardingSphereConnection(databaseName, contextManager, jdbcContext);
}
ShardingSphereConnection的prepareStatement方法创建的是ShardingSpherePreparedStatement,那么最后我们直接看它的executeQuery方法的核心逻辑,因为方法比较长,我们只截取主流程代码
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
// ...... 其它分支,有兴趣自己查看
executionContext = createExecutionContext(queryContext);
List<QueryResult> queryResults = executeQuery0();
MergedResult mergedResult = mergeQuery(queryResults);
List<ResultSet> resultSets = getResultSets();
if (null == columnLabelAndIndexMap) {
columnLabelAndIndexMap = ShardingSphereResultSetUtils.createColumnLabelAndIndexMap(sqlStatementContext, resultSets.get(0).getMetaData());
}
result = new ShardingSphereResultSet(resultSets, mergedResult, this, selectContainsEnhancedTable, executionContext, columnLabelAndIndexMap);
// CHECKSTYLE:OFF
} catch (final RuntimeException ex) {
// CHECKSTYLE:ON
handleExceptionInTransaction(connection, metaDataContexts);
throw SQLExceptionTransformEngine.toSQLException(ex, metaDataContexts.getMetaData().getDatabase(connection.getDatabaseName()).getProtocolType().getType());
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
这个方法虽然不长,但是涵盖我们上面说的主要执行过程,createExecutionContext用于创建执行上下文,主要是做SQL解析和路由两件事情,executeQuery0主要是调用执行引擎来执行SQL,mergeQuery是用来做结果归并,代码是不是非常清晰?确实是值得我们学习,为避免大家陷入代码海洋,今天就点到为止,大家有兴趣可以下载代码进行赏读。
结语,伟大的框架值得我们花时间会研究和阅读,今天是端午节,祝大家端午安康,附上苏轼的词一首
【浣溪沙.端午】 【宋】苏轼 轻汗微微透碧纨,明朝端午浴芳兰。流香涨腻满晴川。 彩线轻缠红玉臂,小符斜挂绿云鬟。佳人相见一千年。
